Chapter 3 Fluency with Files and Directories
Motivating Questions
- How can I create, copy, and delete files and directories?
- How can I edit files?
Objectives
- Create a directory hierarchy that matches a given diagram.
- Create files in that hierarchy using an editor or by copying and renaming existing files.
- Delete, copy and move specified files and/or directories.
Key Points
cp old newcopies a file.mkdir pathcreates a new directory.mv old newmoves (renames) a file or directory.rm pathremoves (deletes) a file.*matches zero or more characters in a filename, so*.txtmatches all files ending in.txt.?matches any single character in a filename, so?.txtmatchesa.txtbut notany.txt.- Use of the Control key may be described in many ways, including
Ctrl-X,Control-X, and^X. - The shell does not have a trash bin: once something is deleted, it’s really gone.
- Depending on the type of work you do, you may need a more powerful text editor than Nano.
We now know how to explore files and directories,
but how do we create them in the first place?
Let’s go back to our data-shell directory on the Desktop
and use ls -F to see what it contains:
$ pwd
/Users/Kendall/Desktop/data-shell
$ ls -F
creatures/ data/ molecules/ north-pacific-gyre/ notes.txt pizza.cfg solar.pdf writing/Let’s create a new directory called thesis using the command mkdir thesis
(which has no output):
$ mkdir thesisAs you might guess from its name,
mkdir means “make directory.”
Since thesis is a relative path
(i.e., doesn’t have a leading slash),
the new directory is created in the current working directory:
$ ls -F
creatures/ data/ molecules/ north-pacific-gyre/ notes.txt pizza.cfg solar.pdf thesis/ writing/Note: Using the shell to create a directory is no different than using a file explorer.
If you open the current directory using your operating system’s graphical file explorer,
the thesis directory will appear there too.
While the shell and the file explorer are two different ways of interacting with the files,
the files and directories themselves are the same.
3.1 Good names for files and directories
Complicated names of files and directories can make your life painful when working on the command line. Here we provide a few useful tips for the names of your files.
Don’t use whitespaces.
Whitespaces can make a name more meaningful but since whitespace is used to break arguments on the command line it is better to avoid them in names of files and directories. You can use
-or_instead of whitespace.Don’t begin the name with
-(dash).Commands treat names starting with
-as options.Stick with letters, numbers,
.(period or ‘full stop’),-(dash) and_(underscore).Many other characters have special meanings on the command line. We will learn about some of these during this lesson. There are special characters that can cause your command to not work as expected and can even result in data loss.
If you need to refer to names of files or directories that have whitespace
or another non-alphanumeric character, you should surround the name in quotes ("").
Since we’ve just created the thesis directory, there’s nothing in it yet:
$ ls -F thesisLet’s change our working directory to thesis using cd,
then run a text editor called Nano to create a file called draft.txt:
$ cd thesis
$ nano draft.txt3.2 Which Editor?
When we say, “nano is a text editor,” we really do mean “text”: it can
only work with plain character data, not tables, images, or any other
human-friendly media. We use nano in examples because it is one of the
least complex text editors. However, because of this trait, it may
not be powerful anough or flexible enough for the work you need to do
after this workshop. On Unix systems (such as Linux and Mac OS X),
many programmers use Emacs or
Vim (both of which require more time to learn),
or a graphical editor such as
Gedit. On Windows, you may wish to
use Notepad++. Windows also has a built-in
editor called notepad that can be run from the command line in the same
way as nano for the purposes of this lesson.
No matter what editor you use, you will need to know where it searches for and saves files. If you start it from the shell, it will (probably) use your current working directory as its default location. If you use your computer’s start menu, it may want to save files in your desktop or documents directory instead. You can change this by navigating to another directory the first time you “Save As…”
Let’s type in a few lines of text.
Once we’re happy with our text, in nano we can press Ctrl-O (press the Ctrl or Control key and, while
holding it down, press the O key) to write our data to disk
(we’ll be asked what file we want to save this to:
press Return to accept the suggested default of draft.txt).
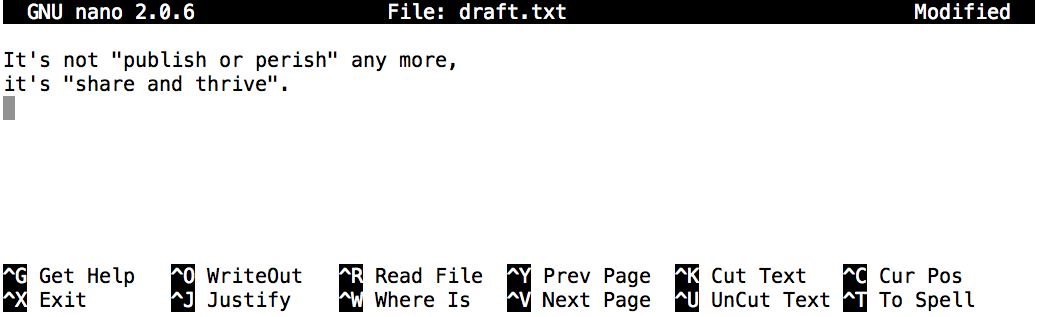
Nano in Action
Once our file is saved, we can use Ctrl-X to quit the editor and
return to the shell.
3.3 Control, Ctrl, or ^ Key
The Control key is also called the “Ctrl” key. There are various ways in which using the Control key may be described. For example, you may see an instruction to press the Control key and, while holding it down, press the X key, described as any of:
Control-XControl+XCtrl-XCtrl+X^XC-x
In nano, along the bottom of the screen you’ll see ^G Get Help ^O WriteOut.
This means that you can use Control-G to get help and Control-O to save your
file.
nano doesn’t leave any output on the screen after it exits,
but ls now shows that we have created a file called draft.txt:
$ ls
draft.txt3.4 Challenge: Creating Files a Different Way
We have seen how to create text files using the nano editor.
Now, try the following command in your home directory:
$ cd # go to your home directory
$ touch my_file.txtWhat did the touch command do? When you look at your home directory using the GUI file explorer, does the file show up?
Use
ls -lto inspect the files. How large ismy_file.txt?When might you want to create a file this way?
Solution
The touch command generates a new file called ‘my_file.txt’ in your home directory. If you are in your home directory, you can observe this newly generated file by typing
lsat the command line prompt. ‘my_file.txt’ can also be viewed in your GUI file explorer.When you inspect the file with
ls -l, note that the size of ‘my_file.txt’ is 0kb. In other words, it contains no data. If you open ‘my_file.txt’ using your text editor it is blank.Some programs do not generate output files themselves, but instead require that empty files have already been generated. When the program is run, it searches for an existing file to populate with its output. The touch command allows you to efficiently generate a blank text file to be used by such programs.
Returning to the data-shell directory,
let’s tidy up the thesis directory by removing the draft we created:
$ cd thesis
$ rm draft.txtThis command removes files (rm is short for “remove”).
If we run ls again,
its output is empty once more,
which tells us that our file is gone:
$ ls3.5 Deleting Is Forever
The Unix shell doesn’t have a trash bin that we can recover deleted files from (though most graphical interfaces to Unix do). Instead, when we delete files, they are unhooked from the file system so that their storage space on disk can be recycled. Tools for finding and recovering deleted files do exist, but there’s no guarantee they’ll work in any particular situation, since the computer may recycle the file’s disk space right away.
Let’s re-create that file
and then move up one directory to /Users/Kendall/Desktop/data-shell using cd ..:
$ pwd
/Users/Kendall/Desktop/data-shell/thesis
$ nano draft.txt
$ ls
draft.txt
$ cd ..If we try to remove the entire thesis directory using rm thesis,
we get an error message:
$ rm thesis
rm: cannot remove `thesis': Is a directoryThis happens because rm by default only works on files, not directories.
To really get rid of thesis we must also delete the file draft.txt.
We can do this with the recursive option for rm:
$ rm -r thesis3.6 Challenge: Using rm Safely
What happens when we execute rm -i thesis/quotations.txt?
Why would we want this protection when using rm?
Solution
$ rm: remove regular file 'thesis/quotations.txt'?The -i flag will prompt before every removal.
Again, the Unix shell doesn’t have a trash bin, so all the files removed will disappear forever.
By using the -i flag, we have the chance to check that we are deleting only the files that we want to remove.
3.7 With Great Power Comes Great Responsibility
Removing the files in a directory recursively can be a very dangerous
operation. If we’re concerned about what we might be deleting we can
add the “interactive” flag -i to rm which will ask us for confirmation
before each step
$ rm -r -i thesis
rm: descend into directory ‘thesis’? y
rm: remove regular file ‘thesis/draft.txt’? y
rm: remove directory ‘thesis’? yThis removes everything in the directory, then the directory itself, asking at each step for you to confirm the deletion.
Let’s create that directory and file one more time.
(Note that this time we’re running nano with the path thesis/draft.txt,
rather than going into the thesis directory and running nano on draft.txt there.)
$ pwd
/Users/Kendall/Desktop/data-shell
$ mkdir thesis
$ nano thesis/draft.txt
$ ls thesis
draft.txtdraft.txt isn’t a particularly informative name,
so let’s change the file’s name using mv,
which is short for “move”:
$ mv thesis/draft.txt thesis/quotes.txtThe first argument tells mv what we’re “moving,”
while the second is where it’s to go.
In this case,
we’re moving thesis/draft.txt to thesis/quotes.txt,
which has the same effect as renaming the file.
Sure enough,
ls shows us that thesis now contains one file called quotes.txt:
$ ls thesis
quotes.txtOne has to be careful when specifying the target file name, since mv will
silently overwrite any existing file with the same name, which could
lead to data loss. An additional flag, mv -i (or mv --interactive),
can be used to make mv ask you for confirmation before overwriting.
Just for the sake of consistency,
mv also works on directories
Let’s move quotes.txt into the current working directory.
We use mv once again,
but this time we’ll just use the name of a directory as the second argument
to tell mv that we want to keep the filename,
but put the file somewhere new.
(This is why the command is called “move.”)
In this case,
the directory name we use is the special directory name . that we mentioned earlier.
$ mv thesis/quotes.txt .The effect is to move the file from the directory it was in to the current working directory.
ls now shows us that thesis is empty:
$ ls thesisFurther,
ls with a filename or directory name as an argument only lists that file or directory.
We can use this to see that quotes.txt is still in our current directory:
$ ls quotes.txt
quotes.txt3.8 Challenge: Moving to the Current Folder
After running the following commands,
Jamie realizes that she put the files sucrose.dat and maltose.dat into the wrong folder:
$ ls -F
analyzed/ raw/
$ ls -F analyzed
fructose.dat glucose.dat maltose.dat sucrose.dat
$ cd raw/Fill in the blanks to move these files to the current folder (i.e., the one she is currently in):
$ mv ___/sucrose.dat ___/maltose.dat ___Solution
$ mv ../analyzed/sucrose.dat ../analyzed/maltose.dat .Recall that .. refers to the parent directory (i.e. one above the current directory)
and that . refers to the current directory.
The cp command works very much like mv,
except it copies a file instead of moving it.
We can check that it did the right thing using ls
with two paths as arguments — like most Unix commands,
ls can be given multiple paths at once:
$ cp quotes.txt thesis/quotations.txt
$ ls quotes.txt thesis/quotations.txt
quotes.txt thesis/quotations.txtTo prove that we made a copy,
let’s delete the quotes.txt file in the current directory
and then run that same ls again.
$ rm quotes.txt
$ ls quotes.txt thesis/quotations.txt
ls: cannot access quotes.txt: No such file or directory
thesis/quotations.txtThis time it tells us that it can’t find quotes.txt in the current directory,
but it does find the copy in thesis that we didn’t delete.
3.9 What’s In A Name?
You may have noticed that all of Kendall’s files’ names are “something dot
something,” and in this part of the lesson–we always used the extension
.txt. This is just a convention: we can call a file mythesis or
almost anything else we want. However, most people use two-part names
most of the time to help them (and their programs) tell different kinds
of files apart. The second part of such a name is called the
filename extension, and indicates
what type of data the file holds: .txt signals a plain text file, .pdf
indicates a PDF document, .cfg is a configuration file full of parameters
for some program or other, .png is a PNG image, and so on.
This is just a convention, albeit an important one. Files contain bytes: it’s up to us and our programs to interpret those bytes according to the rules for plain text files, PDF documents, configuration files, images, and so on.
Naming a PNG image of a whale as whale.mp3 doesn’t somehow
magically turn it into a recording of whalesong, though it might
cause the operating system to try to open it with a music player
when someone double-clicks it.
3.10 Challenge: Renaming Files
Suppose that you created a .txt file in your current directory to contain a list of the
statistical tests you will need to do to analyze your data, and named it: statstics.txt
After creating and saving this file you realize you misspelled the filename! You want to correct the mistake, which of the following commands could you use to do so?
cp statstics.txt statistics.txtmv statstics.txt statistics.txtmv statstics.txt .cp statstics.txt .
Solution
- No. While this would create a file with the correct name, the incorrectly named file still exists in the directory and would need to be deleted.
- Yes, this would work to rename the file.
- No, the period(.) indicates where to move the file, but does not provide a new file name; identical file names cannot be created.
- No, the period(.) indicates where to copy the file, but does not provide a new file name; identical file names cannot be created.
3.11 Challenge: Moving and Copying
What is the output of the closing ls command in the sequence shown below?
$ pwd
/Users/jamie/data
$ ls
proteins.dat
$ mkdir recombine
$ mv proteins.dat recombine/
$ cp recombine/proteins.dat ../proteins-saved.dat
$ lsproteins-saved.dat recombinerecombineproteins.dat recombineproteins-saved.dat
Solution
We start in the /Users/jamie/data directory, and create a new folder called recombine.
The second line moves (mv) the file proteins.dat to the new folder (recombine).
The third line makes a copy of the file we just moved. The tricky part here is where the file was
copied to. Recall that .. means “go up a level,” so the copied file is now in /Users/jamie.
Notice that .. is interpreted with respect to the current working
directory, not with respect to the location of the file being copied.
So, the only thing that will show using ls (in /Users/jamie/data) is the recombine folder.
- No, see explanation above.
proteins-saved.datis located at/Users/jamie - Yes
- No, see explanation above.
proteins.datis located at/Users/jamie/data/recombine - No, see explanation above.
proteins-saved.datis located at/Users/jamie
3.12 Challenge: Copy with Multiple Filenames
For this exercise, you can test the commands in the data-shell/data directory.
In the example below, what does cp do when given several filenames and a directory name?
$ mkdir backup
$ cp amino-acids.txt animals.txt backup/In the example below, what does cp do when given three or more file names?
$ ls -F
amino-acids.txt animals.txt backup/ elements/ morse.txt pdb/ planets.txt salmon.txt sunspot.txt
$ cp amino-acids.txt animals.txt morse.txt Solution
If given more than one file name followed by a directory name (i.e. the destination directory must
be the last argument), cp copies the files to the named directory.
If given three file names, cp throws an error because it is expecting a directory
name as the last argument.
cp: target ‘morse.txt’ is not a directory3.13 Wildcards
* is a wildcard. It matches zero or more
characters, so *.pdb matches ethane.pdb, propane.pdb, and every
file that ends with ‘.pdb.’ On the other hand, p*.pdb only matches
pentane.pdb and propane.pdb, because the ‘p’ at the front only
matches filenames that begin with the letter ‘p.’
? is also a wildcard, but it only matches a single character. This
means that p?.pdb would match pi.pdb or p5.pdb (if we had these two
files in the molecules directory), but not propane.pdb.
We can use any number of wildcards at a time: for example, p*.p?*
matches anything that starts with a ‘p’ and ends with ‘.’ ‘p,’ and at
least one more character (since the ? has to match one character, and
the final * can match any number of characters). Thus, p*.p?* would
match preferred.practice, and even p.pi (since the first * can
match no characters at all), but not quality.practice (doesn’t start
with ‘p’) or preferred.p (there isn’t at least one character after the
‘.p’).
When the shell sees a wildcard, it expands the wildcard to create a
list of matching filenames before running the command that was
asked for. As an exception, if a wildcard expression does not match
any file, Bash will pass the expression as an argument to the command
as it is. For example typing ls *.pdf in the molecules directory
(which contains only files with names ending with .pdb) results in
an error message that there is no file called *.pdf.
However, generally commands like wc and ls see the lists of
file names matching these expressions, but not the wildcards
themselves. It is the shell, not the other programs, that deals with
expanding wildcards, and this is another example of orthogonal design.
3.13.1 Challenge: Using Wildcards
When run in the molecules directory, which ls command(s) will
produce this output?
ethane.pdb methane.pdb
ls *t*ane.pdbls *t?ne.*ls *t??ne.pdbls ethane.*
Solution
The solution is 3.
1. shows all files whose names contain zero or more characters (*) followed by the letter t, then zero or more characters (*) followed by ane.pdb. This gives ethane.pdb methane.pdb octane.pdb pentane.pdb.
2. shows all files whose names start with zero or more characters (*) followed by the letter t, then a single character (?), then ne. followed by zero or more characters (*). This will give us octane.pdb and pentane.pdb but doesn’t match anything which ends in thane.pdb.
3. fixes the problems of option 2 by matching two characters (??) between t and ne. This is the solution.
4. only shows files starting with ethane..
3.13.2 Challenge: More on Wildcards
Sam has a directory containing calibration data, datasets, and descriptions of the datasets:
2015-10-23-calibration.txt
2015-10-23-dataset1.txt
2015-10-23-dataset2.txt
2015-10-23-dataset_overview.txt
2015-10-26-calibration.txt
2015-10-26-dataset1.txt
2015-10-26-dataset2.txt
2015-10-26-dataset_overview.txt
2015-11-23-calibration.txt
2015-11-23-dataset1.txt
2015-11-23-dataset2.txt
2015-11-23-dataset_overview.txtBefore heading off to another field trip, she wants to back up her data and send some datasets to her colleague Bob. Sam uses the following commands to get the job done:
$ cp *dataset* /backup/datasets
$ cp ____calibration____ /backup/calibration
$ cp 2015-____-____ ~/send_to_bob/all_november_files/
$ cp ____ ~/send_to_bob/all_datasets_created_on_a_23rd/Help Sam by filling in the blanks.
Solution
$ cp *calibration.txt /backup/calibration
$ cp 2015-11-* ~/send_to_bob/all_november_files/
$ cp *-23-dataset* ~send_to_bob/all_datasets_created_on_a_23rd/3.14 Challenge: Organizing Directories and Files
Jamie is working on a project and she sees that her files aren’t very well organized:
$ ls -F
analyzed/ fructose.dat raw/ sucrose.datThe fructose.dat and sucrose.dat files contain output from her data
analysis. What command(s) covered in this lesson does she need to run so that the commands below will
produce the output shown?
$ ls -F
analyzed/ raw/
$ ls analyzed
fructose.dat sucrose.datSolution
mv *.dat analyzedJamie needs to move her files fructose.dat and sucrose.dat to the analyzed directory.
The shell will expand *.dat to match all .dat files in the current directory.
The mv command then moves the list of .dat files to the “analyzed” directory.
3.15 Copy a folder structure but not the files
You’re starting a new experiment, and would like to duplicate the file structure from your previous experiment without the data files so you can add new data.
Assume that the file structure is in a folder called ‘2016-05-18-data,’
which contains a data folder that in turn contains folders named raw and
processed that contain data files. The goal is to copy the file structure
of the 2016-05-18-data folder into a folder called 2016-05-20-data and
remove the data files from the directory you just created.
Which of the following set of commands would achieve this objective? What would the other commands do?
$ cp -r 2016-05-18-data/ 2016-05-20-data/
$ rm 2016-05-20-data/raw/*
$ rm 2016-05-20-data/processed/*
$ rm 2016-05-20-data/raw/*
$ rm 2016-05-20-data/processed/*
$ cp -r 2016-05-18-data/ 2016-5-20-data/
$ cp -r 2016-05-18-data/ 2016-05-20-data/
$ rm -r -i 2016-05-20-data/Solution
The first set of commands achieves this objective.
First we have a recursive copy of a data folder.
Then two rm commands which remove all files in the specified directories.
The shell expands the ’*’ wild card to match all files and subdirectories.
The second set of commands have the wrong order: attempting to delete files which haven’t yet been copied, followed by the recursive copy command which would copy them.
The third set of commands would achieve the objective, but in a time-consuming way: the first command copies the directory recursively, but the second command deletes interactively, prompting for confirmation for each file and directory.